Creating a dump
Creating a dump in Meilisearch Cloud
You cannot manually export dumps in Meilisearch Cloud. To migrate your project to the most recent Meilisearch release, use the Cloud interface: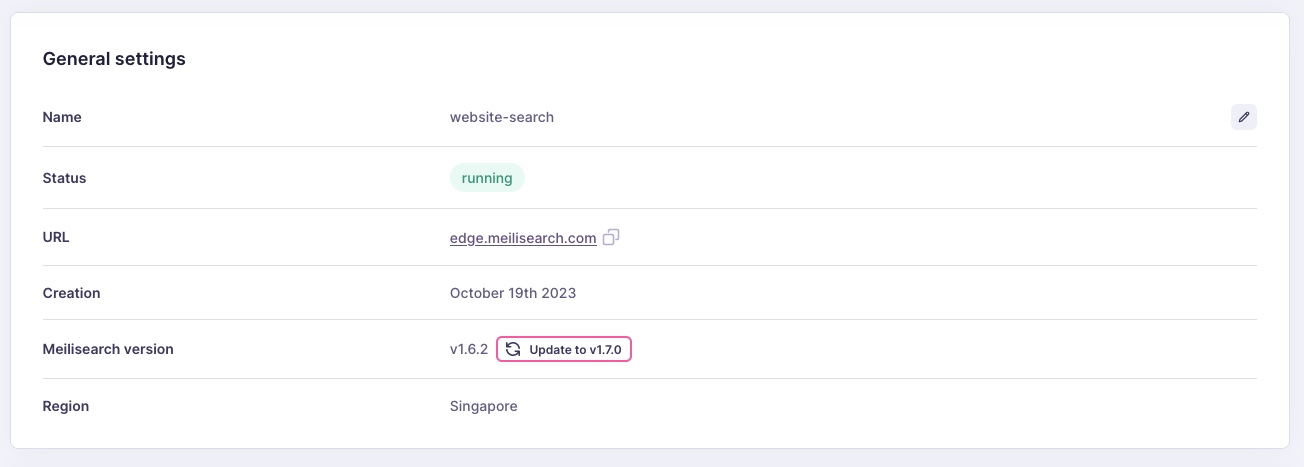
Creating a dump in a self-hosted instance
To create a dump, use the create a dump endpoint:1 with the taskUid returned by the previous command:
.dump file. The dump also includes any tasks registered before Meilisearch starts processing the dump creation task.
Once the task status changes to succeeded, find the dump file in the dump directory. By default, this folder is named dumps and can be found in the same directory where you launched Meilisearch.
If a dump file is visible in the file system, the dump process was successfully completed. Meilisearch will never create a partial dump file, even if you interrupt an instance while it is generating a dump.
Since the
key field depends on the master key, it is not propagated to dumps. If a malicious user ever gets access to your dumps, they will not have access to your instance’s API keys.Importing a dump
Import a dump by launching a Meilisearch instance with the--import-dump configuration option:
uid as an index in the dump file will be overwritten.
Do not use dumps to migrate from a new Meilisearch version to an older release. Doing so might lead to unexpected behavior.